Data Graph
Unify requires a Business tier account and is included with Engage.
See the available plans, or contact Support.
The Data Graph acts as a semantic layer that allows businesses to define relationships between various entity datasets in the warehouse — such as accounts, subscriptions, households, and products — with the Segment Profile. It makes these relational datasets easily accessible to business teams for targeted and personalized customer engagements.
- Linked Audiences: Empowers marketers to effortlessly create targeted audiences by combining behavioral data from the Segment Profile and warehouse entity data within a self-serve, no-code interface. This tool accelerates audience creation, enabling precise targeting, enhanced customer personalization, and optimized marketing spend without the need for constant data team support.
- Linked Events: Allows data teams to enrich event streams in real time using datasets from data warehouses or lakes, and send these enriched events to any destination. Linked Events is available for both Destination Actions and Functions.
Prerequisites
To use the Data Graph, you’ll need the following:
- A supported data warehouse with the appropriate Data Graph permissions
- Workspace Owner or Unify Read-only/Admin and Entities Admin permissions
- For Linked Audiences, set up Profiles Sync in a Unify space with ready-to-use data models and tables in your warehouse. When setting up selective sync, Segment recommends the following settings:
- Under Profile materialized tables, select all the tables (
user_identifier,user_traits,profile_merges) for faster and more cost-efficient Linked Audiences computations in your data warehouse. - Under Track event tables, select Sync all Track Call Tables to enable filtering on event history for Linked Audiences conditions.
- Under Profile materialized tables, select all the tables (
Step 1: Set up Data Graph permissions in your data warehouse
Data Graph, Reverse ETL, and Profiles Sync require different warehouse permissions.
Data Graph currently only supports workspaces in the United States.
To get started with the Data Graph, set up the required permissions in your warehouse. Segment supports the following:
- Linked Audiences: Snowflake and Databricks
- Linked Events: Snowflake, Databricks, BigQuery, and Redshift
To track the data sent to Segment on previous syncs, Segment uses Reverse ETL infrastructure to store diffs in tables within a dedicated schema called _segment_reverse_etl in your data warehouse. You can choose which database or project in your warehouse this data lives in.
Step 2: Connect your warehouse to the Data Graph
To connect your warehouse to the Data Graph:
- Navigate to Unify > Data Graph. This should be a Unify space with Profiles Sync already set up.
- Click Add warehouse.
- Select your warehouse type.
- Enter your warehouse credentials.
- Test your connection, then click Save.
Step 3: Build your Data Graph
The Data Graph is a semantic layer that represents a subset of relevant business data that marketers and business stakeholders can use for audience targeting and personalization in downstream tools. Use the configuration language spec and the following features to build your Data Graph:
- Use the Warehouse access tab to view the warehouse tables you’ve granted Segment access to
- Begin typing to autopopulate the configuration spec within the editor, as well as to autocomplete your warehouse schema
- Validate your Data Graph using the Preview tab
Key steps to build your Data Graph
- First, define your entities. An entity corresponds to a table in your warehouse. Segment flexibly supports tables, views and materialized views.
- Then, define the profile block. This is a special class of entity that represents Segment Profiles, which corresponds to the Profiles Sync tables and models. For Linked Audiences, this allows marketers to filter on profile traits, event history, and so on.
- Finally, define how your datasets are related to each other. The Data Graph preserves these relationships and carries this rich context to the destinations to unlock personalization.
Defining Relationships
Similar to the concept of cardinality in data modeling, the Data Graph supports 3 types of relationships:
- Profile-to-entity relationship: This is a relationship between your entity table and the Segment Profiles tables, and is the first level of relationship.
- 1:many relationship: For example, an
accountcan have manycarts, but eachcartcan only be associated with oneaccount. - many:many relationship: For example, a user can have many
carts, and eachcartcan have manyproducts. However, theseproductscan also belong to manycarts. - The Data Graph currently supports 6 levels of depth (or nodes) starting from the profile. For example, relating the
profileto theaccountstable to thecartstable is 3 levels of depth. There are no limits on the width of your Data Graph or the number of entities. - Relationships are nested under the profile. Refer to the example below.
Data Graph Example
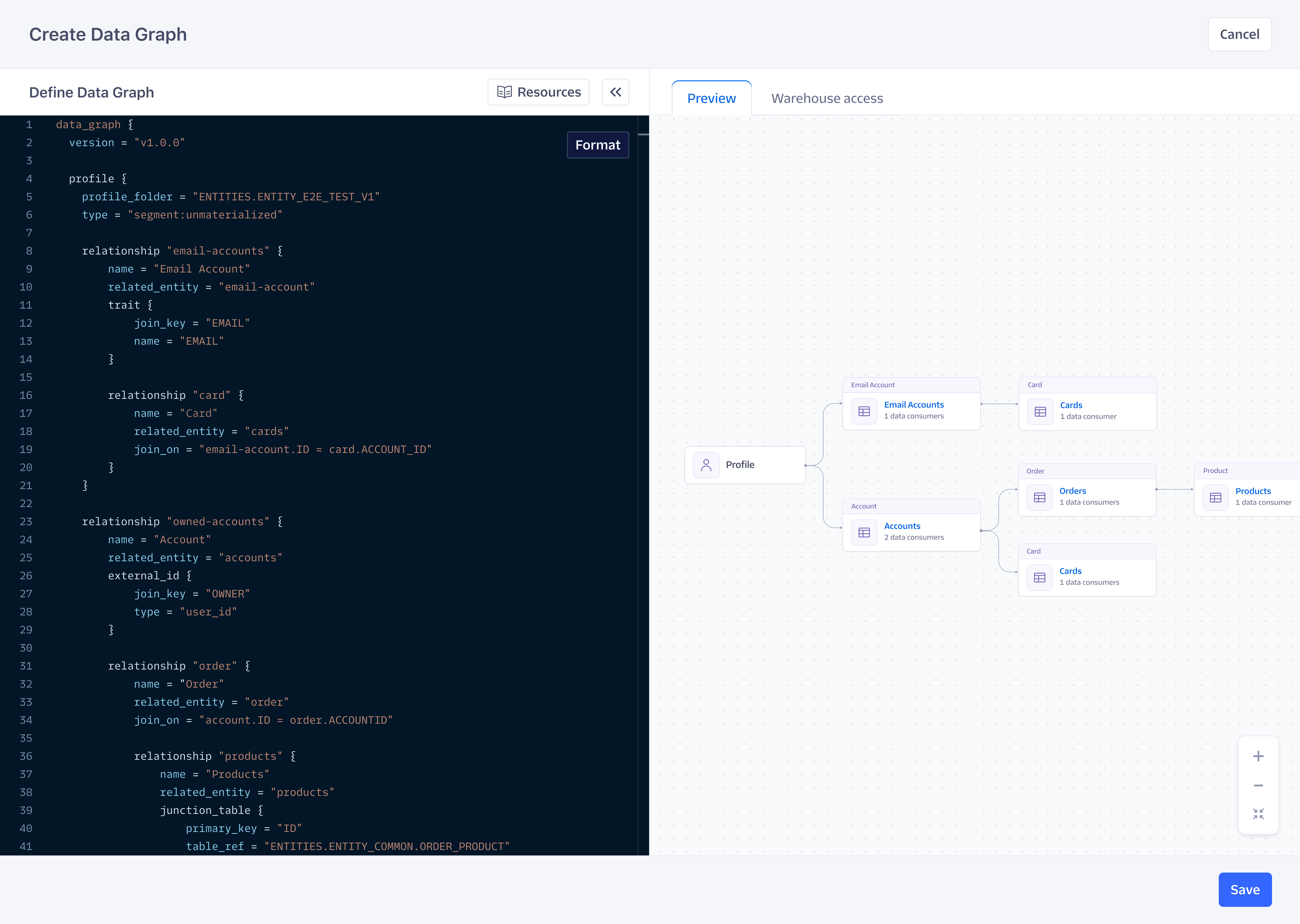
data_graph {
version = "v1.0.0"
# Define entities
entity "account-entity" {
name = "account"
table_ref = "PRODUCTION.CUST.ACCOUNT"
primary_key = "ID"
}
entity "product-entity" {
name = "product"
table_ref = "PRODUCTION.PROD.PRODUCT_SKUS"
primary_key = "SKU"
}
entity "cart-entity" {
name = "cart"
table_ref = "PRODUCTION.CUST.CART"
primary_key = "ID"
enrichment_enabled = true
}
entity "household-entity" {
name = "household"
table_ref = "PRODUCTION.CUST.HOUSEHOLD"
primary_key = "HOUSEHOLD_ID"
}
entity "subscription-entity" {
name = "subscription"
table_ref = "PRODUCTION.CUST.SUBSCRIPTION"
primary_key = "SUB_ID"
}
# Define the profile entity, which corresponds to Segment Profiles tables synced via Profiles Sync
# Recommend setting up Profiles Sync materialized views to optimize warehouse compute costs
profile {
profile_folder = "PRODUCTION.SEGMENT"
type = "segment:materialized"
# First branch - relate accounts table to the profile
# This is a unique type of relationship between an entity and the profile block
relationship "user-accounts" {
name = "Premium Accounts"
related_entity = "account-entity"
# Join the profile entity with an identifier (e.g. email) on the related entity table
# Option to replace with the traits block below to join with a profile trait on the entity table instead
external_id {
type = "email"
join_key = "EMAIL_ID"
}
# Define 1:many relationship between accounts and carts
# e.g. an account can be associated with many carts
relationship "user-carts" {
name = "Shopping Carts"
related_entity = "cart-entity"
join_on = "account-entity.ID = cart-entity.ACCOUNT_ID"
# Define many:many relationship between carts and products
# e.g. there can be multiple carts, and each cart can be associated with multiple products
relationship "products" {
name = "Purchased Products"
related_entity = "product-entity"
junction_table {
primary_key = "ID"
table_ref = "PRODUCTION.CUSTOMER.CART_PRODUCT"
left_join_on = "cart-entity.ID = CART_ID"
right_join_on = "PRODUCT_ID = product-entity.SKU"
}
}
}
}
# Second branch - relate households table to the profile by joining with an external ID block
relationship "user-households" {
name = "Households"
related_entity = "household-entity"
external_id {
type = "email"
join_key = "EMAIL_ID"
}
# Define 1:many relationship between households and subscriptions
# e.g. a household can be associated with multiple subscriptions
relationship "user-subscriptions" {
name = "Subscriptions"
related_entity = "subscription-entity"
join_on = "household-entity.SUB_ID = subscription-entity.HOUSEHOLD_ID"
}
}
3a: Define entities
The first step in creating a Data Graph is to define your entities. An entity corresponds to a table in the warehouse.
| Parameters | Definition |
|---|---|
entity |
An immutable slug for the entity, and will be treated as a delete if you make changes. The slug must be in all lowercase, and supports dashes or underscores (e.g account-entity or account_entity). |
name |
A label displayed throughout your Segment space for Linked Events, Linked Audiences, etc. This name can be modified at any time. |
table_ref |
Defines the fully qualified table reference: [database name].[schema name].[table name]. Segment flexibly supports tables, views and materialized views. |
primary_key |
The unique identifier for the given table. Must be a column with unique values per row. |
(If applicable) enrichment_enabled = true |
Add this if you plan to reference the entity table for Linked Events use cases. |
Example:
data_graph {
entity "account-entity" {
name = "account"
table_ref = "PRODUCTION.CUST.ACCOUNT"
primary_key = "ID"
}
entity "cart-entity" {
name = "cart"
table_ref = "PRODUCTION.CUST.CART"
primary_key = "ID"
enrichment_enabled = true
}
}
3b: Define the profile
Segments recommends that you select materialized views under the Profiles Selective Sync settings to optimize warehouse compute costs.
Next, define the profile. This is a special class of entity that represents Segment Profiles, which corresponds to the Profiles Sync tables and models. For Linked Audiences, this allows marketers to filter on profile traits, event history, etc. There can only be one profile for a Data Graph.
| Parameters | Definition |
|---|---|
profile_folder |
Define the fully qualified path of the folder or schema location for the profile tables. |
type |
Identify the materialization method of the profile tables defined in your Profiles Sync configuration under Selective Sync settings: segment:unmaterialized or segment:materialized. |
Example:
data_graph {
# Define entities
...
# Define the profile entity, which corresponds to Segment Profiles tables synced via Profiles Sync
# Recommend setting up Profiles Sync materialized views to optimize warehouse compute costs
profile {
profile_folder = "PRODUCTION.SEGMENT"
type = "segment:materialized"
}
}
3c: Define relationships
Now define your relationships between your entities. Similar to the concept of cardinality in data modeling, the Data Graph supports 3 types of relationships below. All relationship types require you to define the relationship slug, name, and related entity. Each type of relationship has unique join on conditions.
- Profile-to-entity relationship: This is a relationship between your entity table and the Segment Profiles tables, and is the first level of relationship.
- 1:many relationship: For example, an
accountcan have manycarts, but eachcartcan only be associated with oneaccount. - many:many relationship: For example, a user can have many
carts, and eachcartcan have manyproducts. However, theseproductscan also belong to manycarts.
Define profile-to-entity relationship
This is the first level of relationships and a unique type of relationship between the Segment profile entity and a related entity.
| Parameters | Definition |
|---|---|
relationship |
An immutable slug for the relationship, and will be treated as a delete if you make changes. The slug must be in all lowercase, and supports dashes or underscores (e.g. user-account or user_account) |
name |
A label displayed throughout your Segment space for Linked Events, Linked Audiences, etc. This name can be modified at any time |
related_entity |
References your already defined entity |
To define a profile-to-entity relationship, reference your entity table and depending on your table columns, choose to join on one of the following:
Option 1 (Most common) - Join on an external ID: Use the external_id block to join the profile entity with an entity table using external IDs from your Unify ID resolution settings. Typically these identifiers are user_id, email, or phone depending on the column in the entity table that you want to join with.
type: Represents the external ID type (email,phone,user_id) in your id-res settings. Depending on if you are using materialized or unmaterialized profiles, these correspond to different columns in your Profiles Sync warehouse tables:- Materialized (Recommended): This corresponds to the
typecolumn in your Profiles Syncuser_identifierstable. - Unmaterialized: This corresponds to the
external_id_typecolumn in your Profiles Syncexternal_id_mapping_updatestable.
- Materialized (Recommended): This corresponds to the
join_key: This is the column on the entity table that you are matching to the external identifier.
Option 2 - Join on a profile trait: Use the traits block to join the profile entity with an entity table using Profile Traits.
name: Represents a trait name in your Unify profiles. Depending on if you are using materialized or unmaterialized profiles, these correspond to different columns in your Profiles Sync warehouse tables:- Materialized (Recommended): The trait name corresponds to a unique value of the
namecolumn in your Profiles Syncuser_traitstable. - Unmaterialized: This corresponds to a column in the Profile Sync
profile_trait_updatestable.
- Materialized (Recommended): The trait name corresponds to a unique value of the
join_key: This is the column on the entity table that you are matching to the trait.
Example:
data_graph {
entity "account-entity" {
name = "account"
table_ref = "PRODUCTION.CUST.ACCOUNT"
primary_key = "ID"
}
# Define additional entities...
# Note: Relationships are nested
profile {
profile_folder = "PRODUCTION.SEGMENT"
type = "segment:materialized"
# Relate accounts table to the profile
relationship "user-accounts" {
name = "Premium Accounts"
related_entity = "account-entity"
# Option 1: Join the profile entity with an identifier (e.g. email) on the related entity table
external_id {
type = "email"
join_key = "EMAIL_ID"
}
# Option 2: Join the profile entity with a profile trait on the related entity table
trait {
name = "cust_id"
join_key = "ID"
}
}
}
}
Define a 1:many relationship
For 1:many relationships, define the join on between the two entity tables using the spec below.
| Parameters | Definition |
|---|---|
relationship |
An immutable slug for the relationship, and will be treated as a delete if you make changes. The slug must be in all lowercase, and supports dashes or underscores (e.g. user-account or user_account) |
name |
A label displayed throughout your Segment space for Linked Events, Linked Audiences, and so on. This name can be modified at any time |
related_entity |
References your already defined entity |
join_on |
Defines relationship between the two entity tables [lefty entity slug].[column name] = [right entity slug].[column name]. Note that since you’re referencing the entity slug for the join on, you do not need to define the full table reference |
Example:
data_graph {
entity "cart-entity" {
name = "cart"
table_ref = "PRODUCTION.CUST.CART"
primary_key = "ID"
}
# Define additional entities...
# Note: Relationships are nested
profile {
profile_folder = "PRODUCTION.SEGMENT"
type = "segment:materialized"
relationship "user-accounts" {
...
# Define 1:many relationship between accounts and carts
relationship "user-carts" {
name = "Shopping Carts"
related_entity = "carts-entity"
join_on = "account-entity.ID = cart-entity.ACCOUNT_ID"
}
}
}
}
Define many:many relationship
For many:many relationships, define the join on between the two entity tables with the junction_table.
Attributes from a junction table are not referenceable via the Linked Audience builder. If a marketer would like to filter upon a column on the junction table, you must define the junction as an entity and define a relationship.
| Parameters | Definition |
|---|---|
relationship |
An immutable slug for the relationship, and will be treated as a delete if you make changes. The slug must be in all lowercase, and supports dashes or underscores (e.g. user-account or user_account) |
name |
A label displayed throughout your Segment space for Linked Events, Linked Audiences, and so on. This name can be modified at any time |
related_entity |
References your already defined entity |
Junction table spec
| Parameters | Definition |
|---|---|
table_ref |
Defines the fully qualified table reference to the join table: [database name].[schema name].[table name]. Segment flexibly supports tables, views and materialized views |
primary_key |
The unique identifier for the given table. Must be a column with unique values per row |
left_join_on |
Define the relationship between the left entity table and the junction table: [left entity slug].[column name] = [junction table column name]. Note that schema and table are implied within the junction table column name, so you do not need to define it again |
right_join_on |
Define the relationship between the junction table and the right entity table: [junction table column name] = [right entity slug].[column name]. Note that schema and table are implied within the junction table column name, so you do not need to define it again |
Example:
data_graph {
# Define entities
# Note: Relationships are nested
profile {
# Define profile
relationship "user-accounts" {
...
relationship "user-carts" {
...
# Define many:many relationship between carts and products
relationship "products" {
name = "Purchased Products"
related_entity = "product-entity"
junction_table {
table_ref = "PRODUCTION.CUSTOMER.CART_PRODUCT"
primary_key = "ID"
left_join_on = "cart-entity.ID = CART_ID"
right_join_on = "PRODUCT_ID = product-entity.SKU"
}
}
}
}
}
}
Step 4: Validate your Data Graph
You can validate your Data Graph using the preview, then click Save. After you’ve set up your Data Graph, your partner teams can start leveraging these datasets with with Linked Events and Linked Audiences.
Edit and manage your Data Graph
To edit your Data Graph:
- Navigate to Unify > Data Graph.
- Select the Overview tab, and click Edit Data Graph.
View Data Graph data consumers
A data consumer refers to a Segment feature like Linked Events and Linked Audiences that are referencing datasets, such as entities and/or relationships, from the Data Graph. You can view a list of data consumers in two places:
- Under Unify > Data Graph, click the Data consumers tab
- Under Unify > Data Graph > Overview or the Data Graph editor > Preview, click into a node on the Data Graph preview and a side sheet will pop up with the list of data consumers for the respective relationship
Understand changes that may cause breaking and potential breaking changes
Upon editing and saving changes to your Data Graph, a modal will pop up to warn of breaking and/or potential breaking changes to your data consumers. You must acknowledge and click Confirm and save in order to proceed.
- Definite breaking change: Occurs when deleting an entity or relationship that is being referenced by a data consumer. Data consumers affected by breaking changes will fail on the next run. Note: The entity and relationship slug are immutable and treated as a delete if you make changes. You can modify the label.
- Potential breaking change: Some changes such as updating the entity
table_reforprimary_key, may lead to errors with data consumers. If there’s a breaking change, the data consumer will fail on the next run. Unaffected data consumers will continue to work.
Detect warehouse breaking changes
Segment has a service that regularly scans and monitors the Data Graph for changes that occur in your warehouse that may break components of the Data Graph, such as when the table being referenced by the Data Graph gets deleted from your warehouse or when the primary key column no longer exists. An alert banner will be displayed on the Data Graph landing page. The banner will be removed once the issues are resolved in your warehouse and/or the Data Graph. You will also have the option to trigger a manual sync of your warehouse schema.
This page was last modified: 22 Aug 2024
Need support?
Questions? Problems? Need more info? Contact Segment Support for assistance!